
DP-750 Practice Questions
Implementing Data Engineering Solutions Using Azure Databricks
Last Update 4 days ago
Total Questions : 58
Dive into our fully updated and stable DP-750 practice test platform, featuring all the latest Microsoft Certified: Azure Databricks Data Engineer exam questions added this week. Our preparation tool is more than just a Microsoft study aid; it's a strategic advantage.
Our free Microsoft Certified: Azure Databricks Data Engineer practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about DP-750. Use this test to pinpoint which areas you need to focus your study on.

You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements.
What should you do?
You need to complete the PySpark code for the Spark Structured Streaming pipelines. The solution must meet the data ingestion and processing requirements.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You need to develop the task logic for a new job in Lakeflow Jobs that processes telemetry data.
Each task must contain only the appropriate logic for its step in the pipeline. The solution must support the planned changes and meet the data ingestion and processing requirements.
What should you do?
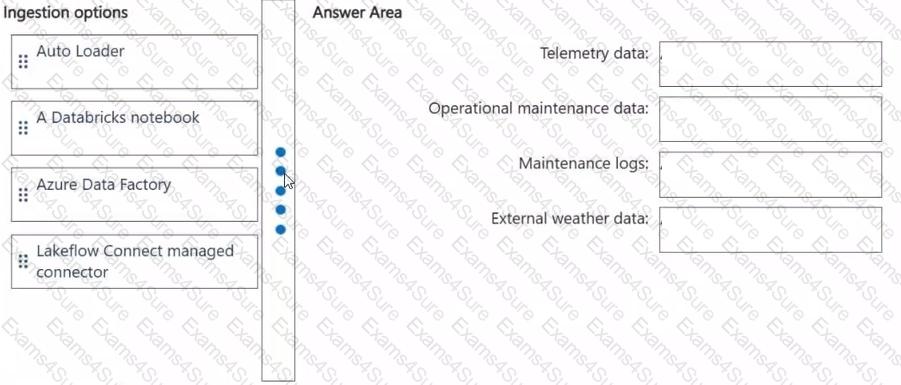
Which ingestion option should you recommend for each data source? To answer, drag the appropriate options to the correct data sources. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Which SCD type should you use to support the planned data modeling changes? To answer, drag the appropriate types to the correct issues. Each type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


You have an Azure Databricks workspace that uses Unity Catalog.
You have a Lakeflow Spark Declarative Pipelines (SDP) pipeline that ingests data into a managed Delta table named Table1. Table! is used for analytics.
New columns are added to the source data, causing pipeline failures during writes to Table!
You need to prevent the pipeline failures. The solution must ensure that schema changes are detected and handled.
What should you do?
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You need to recommend a pipeline that ingests files from cloud storage, performs cleansing and enrichment transformations, and writes created Delta tables for analytics. The solution must minimize development effort and provide built-in monitoring and automatic retries.
What should you include in the recommendation?
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You have a Lakeflow Spark Declarative Pipelines (SDP) pipeline that writes numerical data to a table named Table1 by using a data quality validation rule named rule1.
You need to modify rule1 to meet the following requirements:
Ensure that amount is always greater than 0.
Prevent an update to Table1 from being committed when data that violates rule1 is detected.
Which statement should you execute?
You have an Azure Databricks workspace that is enabled for Unity Catalog
You plan to ingest data from CSV files stored in Azure Data Lake Storage Gen2. New rows are appended frequently.
You need to implement a data ingestion solution that meets the following requirements:
• New data must be available in near-real time (NRT).
• The data must be stored in managed Delta tables.
• The solution must minimize custom code and maintenance effort.
What should you include in the solution?

