
NCA-6.5 Practice Questions
Nutanix Certified Associate (NCA) v6.5 exam
Last Update 1 day ago
Total Questions : 133
Dive into our fully updated and stable NCA-6.5 practice test platform, featuring all the latest Nutanix Certified Associate (NCA) exam questions added this week. Our preparation tool is more than just a Nutanix study aid; it's a strategic advantage.
Our free Nutanix Certified Associate (NCA) practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about NCA-6.5. Use this test to pinpoint which areas you need to focus your study on.

An application owner had reported that an AHV-based critical application VM is performing very slowly. After initial diagnostics, it has been observed that the CPU utilization is significantly higher than normal.
What two actions should the administrator take on this VM without shutting it down? (Choose two.)
Refer to the exhibit.
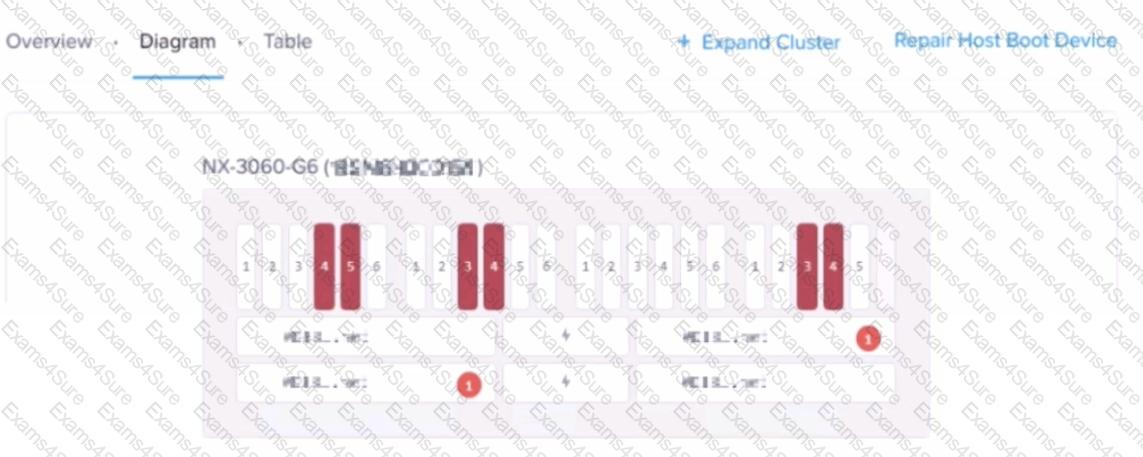
After an abrupt power outage, an administrator receives a number of alerts indicating disks are failed. Prism Element shows a large number of disks offline as seen in the diagram. This single block, four node cluster is configured FT1 with an RF2 container holding all user data.
What number of drive failures on different domains (node, block, or rack) could this configuration have tolerated prior to seeing data unavailability?
An administrator receives several alerts indicating a Nutanix cluster is running out of memory. As a preemptive measure, the administrator wishes to try to reduce the consumed resources, if possible.
Which two predefined views for Reporting best display potentially reclaimable resources? (Choose two.)
An Administrator needs to provide users access to prism Central Projects.
What Source of user accounts must the administrator Use?
What is required to successfully live migrate a VM Between two AHV clusters?
Which address allows external connections to Nutanix storage presented by the Volumes feature?
An administrator needs to deploy a two-node cluster on a new ROBO Site. What is required to maintain High Availability in the case of a node failure?

