
DP-100 Practice Questions
Designing and Implementing a Data Science Solution on Azure
Last Update 2 days ago
Total Questions : 525
Dive into our fully updated and stable DP-100 practice test platform, featuring all the latest Microsoft Azure exam questions added this week. Our preparation tool is more than just a Microsoft study aid; it's a strategic advantage.
Our free Microsoft Azure practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about DP-100. Use this test to pinpoint which areas you need to focus your study on.

You manage an Azure Machine Learning workspace named workspace!.
You plan to author custom pipeline components by using Azure Machine Learning Python SDK v2.
You must transform the Python code into a YAML specification that can be processed by the pipeline service.
You need to import the Python library that provides the transformation functionality.
Which Python library should you import?
You are a data scientist creating a linear regression model.
You need to determine how closely the data fits the regression line.
Which metric should you review?
You manage an Azure Machine Learning workspace. You train a model named model1.
You must identify the features to modify for a differing model prediction result.
You need to configure the Responsible Al (RAI) dashboard for model1.
Which three actions should you perform in sequence? To answer move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
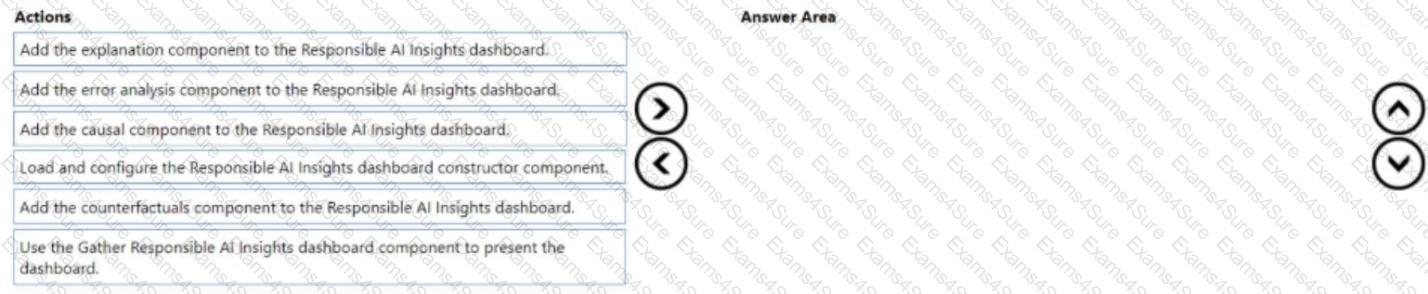

Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are analyzing a numerical dataset which contains missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set.
You need to analyze a full dataset to include all values.
Solution: Remove the entire column that contains the missing data point.
Does the solution meet the goal?
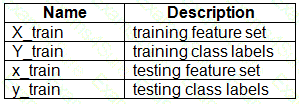
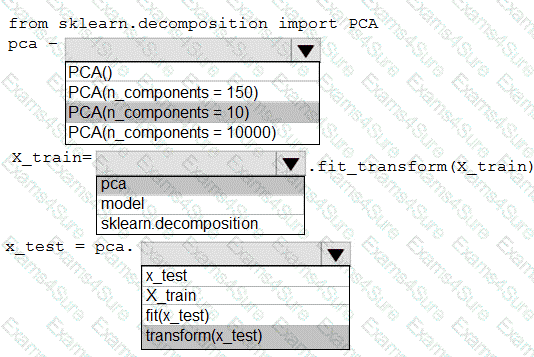
You have a dataset created for multiclass classification tasks that contains a normalized numerical feature set with 10,000 data points and 150 features.
You use 75 percent of the data points for training and 25 percent for testing. You are using the scikit-learn machine learning library in Python. You use X to denote the feature set and Y to denote class labels.
You create the following Python data frames:
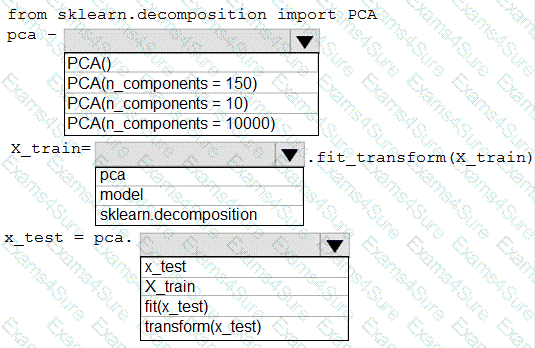
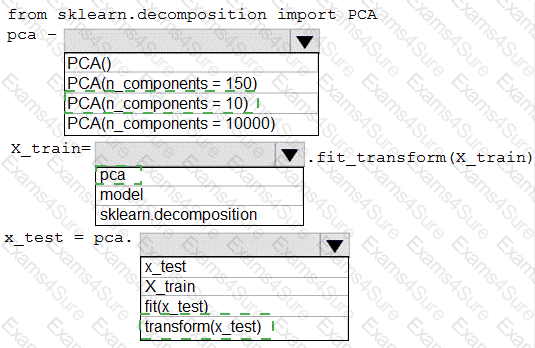
You need to apply the Principal Component Analysis (PCA) method to reduce the dimensionality of the feature set to 10 features in both training and testing sets.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to use a Python script to run an Azure Machine Learning experiment. The script creates a reference to the experiment run context, loads data from a file, identifies the set of unique values for the label column, and completes the experiment run:
from azureml.core import Run
import pandas as pd
run = Run.get_context()
data = pd.read_csv( ' data.csv ' )
label_vals = data[ ' label ' ].unique()
# Add code to record metrics here
run.complete()
The experiment must record the unique labels in the data as metrics for the run that can be reviewed later.
You must add code to the script to record the unique label values as run metrics at the point indicated by the comment.
Solution: Replace the comment with the following code:
run.upload_file( ' outputs/labels.csv ' , ' ./data.csv ' )
Does the solution meet the goal?
You manage an Azure Machine Learning workspace.
You must provide explanations for the behavior of the models with feature importance measures.
You need to configure a Responsible Al dashboard in Azure Machine Learning.
Which dashboard component should you configure?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create a model to forecast weather conditions based on historical data.
You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to a machine learning model training script.
Solution: Run the following code:
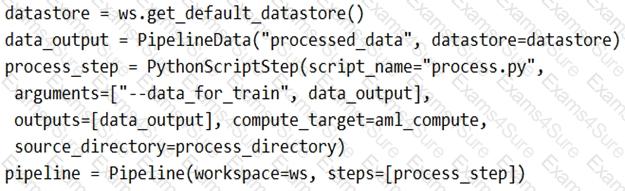
Does the solution meet the goal?
You use an Azure Machine Learning workspace.
You have a trained model that must be deployed as a web service. Users must authenticate by using Azure Active Directory.
What should you do?
You use an Azure Machine Learning workspace. Azure Data Factor/ pipeline, and a dataset monitor that runs en a schedule to detect data drift.
You need to Implement an automated workflow to trigger when the dataset monitor detects data drift and launch the Azure Data Factory pipeline to update the dataset. The solution must minimize the effort to configure the workflow.
How should you configure the workflow? To answer select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.



