DP-100 Practice Questions
Designing and Implementing a Data Science Solution on Azure
Last Update 2 days ago
Total Questions : 525
Dive into our fully updated and stable DP-100 practice test platform, featuring all the latest Microsoft Azure exam questions added this week. Our preparation tool is more than just a Microsoft study aid; it's a strategic advantage.
Our free Microsoft Azure practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about DP-100. Use this test to pinpoint which areas you need to focus your study on.

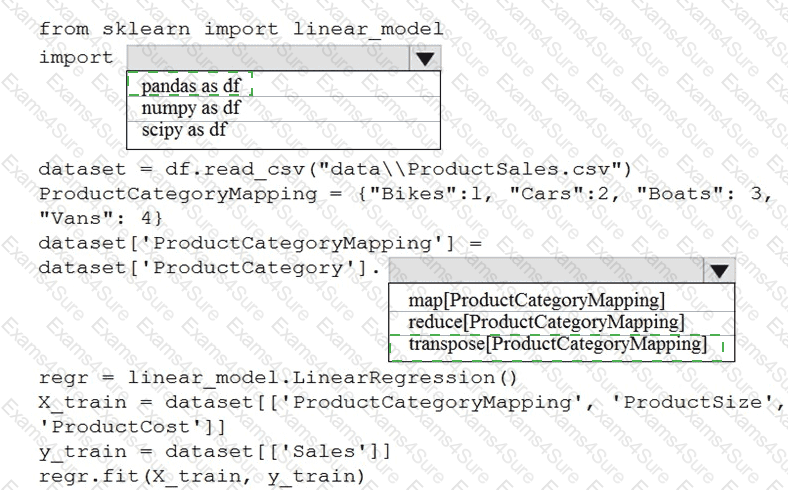
You are creating a machine learning model in Python. The provided dataset contains several numerical columns and one text column. The text column represents a product ' s category. The product category will always be one of the following:
Bikes
Cars
Vans
Boats
You are building a regression model using the scikit-learn Python package.
You need to transform the text data to be compatible with the scikit-learn Python package.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You create a binary classification model by using Azure Machine Learning Studio.
You must tune hyperparameters by performing a parameter sweep of the model. The parameter sweep must meet the following requirements:
iterate all possible combinations of hyperparameters
minimize computing resources required to perform the sweep
You need to perform a parameter sweep of the model.
Which parameter sweep mode should you use?
You plan to implement an Azure Machine Learning solution. You have the following requirements:
• Run a Jupyter notebook to interactively tram a machine learning model.
• Deploy assets and workflows for machine learning proof of concept by using scripting rather than custom programming.
You need to select a development technique for each requirement
Which development technique should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You are solving a classification task.
You must evaluate your model on a limited data sample by using k-fold cross validation. You start by
configuring a k parameter as the number of splits.
You need to configure the k parameter for the cross-validation.
Which value should you use?
You develop a flow for an Azure Al Foundry project.
You plan to use outputs generated by running the flow to determine the following information:
• the number of tokens used by each large language model (LLM) node of the flow
• the accuracy of the model used by the flow
You need to examine the output that provides the required information.
Which output type should you examine? To answer, move the appropriate output types to the correct evaluations. You may use each output type once, more than once, or not at all. You may need to move the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


You train a machine learning model by using Aunt Machine Learning.
You use the following training script m Python to log an accuracy value.

You must use a Python script to define a sweep job.
You need to provide the primary metric and goal you want hyper parameter tuning to optimize.
How should you complete the Python script? To answer select the appropriate options in the answer area
NOTE: Each correct selection is worth one point.


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are analyzing a numerical dataset which contains missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set.
You need to analyze a full dataset to include all values.
Solution: Replace each missing value using the Multiple Imputation by Chained Equations (MICE) method.
Does the solution meet the goal?
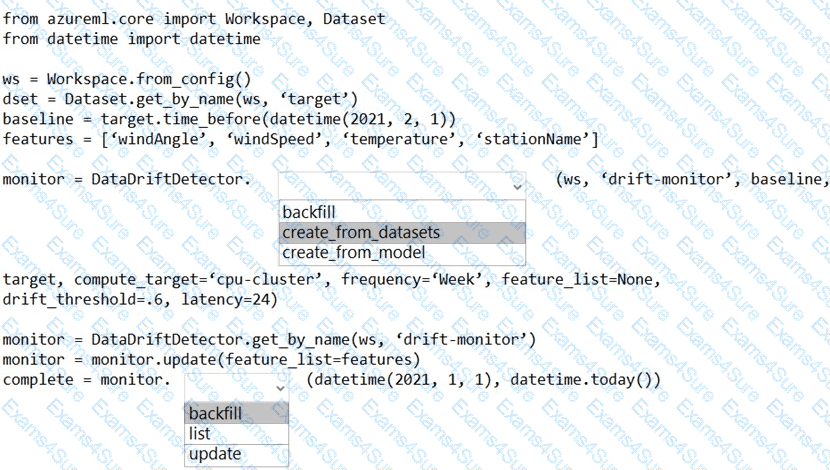
You create an Azure Machine Learning workspace.
You need to detect data drift between a baseline dataset and a subsequent target dataset by using the DataDriftDetector class.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You are developing a machine learning, experiment by using Azure. The following images show the input and output of a machine learning experiment:

Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.


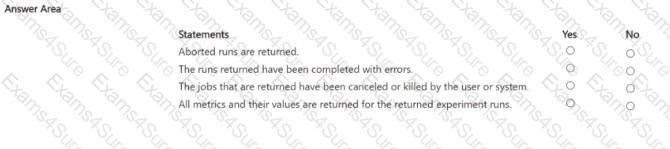
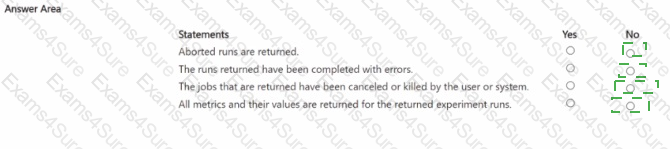
You manage an Azure Machine Learning workspace. You create an experiment named experiment1 by using the Azure Machine Learning Python SDK v2 and MLflow. You are reviewing the results of experiment1 by using the following code segment:

For each of the following statements, Select Yes if the statement is true Otherwise, select No.