DP-100 Practice Questions
Designing and Implementing a Data Science Solution on Azure
Last Update 2 days ago
Total Questions : 525
Dive into our fully updated and stable DP-100 practice test platform, featuring all the latest Microsoft Azure exam questions added this week. Our preparation tool is more than just a Microsoft study aid; it's a strategic advantage.
Our free Microsoft Azure practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about DP-100. Use this test to pinpoint which areas you need to focus your study on.

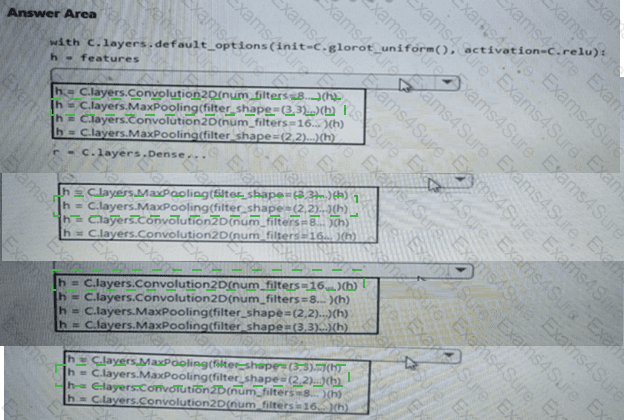
You create an Azure Machine Learning compute resource to train models. The compute resource is configured as follows:
Minimum nodes: 2
Maximum nodes: 4
You must decrease the minimum number of nodes and increase the maximum number of nodes to the following values:
Minimum nodes: 0
Maximum nodes: 8
You need to reconfigure the compute resource.
What are three possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
You ate reviewing model benchmarks in Azure Al Foundry.
You must use an embedding model that can assess rank-order relevance based on cosine similarity. You need to select the applicable embedding model. Which model metric should you focus on?
You have an Azure Machine Learning workspace named Workspace 1 Workspace! has a registered Mlflow model named model 1 with PyFunc flavor
You plan to deploy model1 to an online endpoint named endpoint1 without egress connectivity by using Azure Machine learning Python SDK vl
You have the following code:
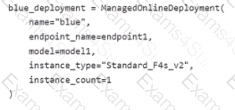
You need to add a parameter to the ManagedOnllneDeployment object to ensure the model deploys successfully
Solution: Add the scoring_script parameter.
Does the solution meet the goal?
You create an Azure Machine Learning pipeline named pipeline1 with two steps that contain Python scripts. Data processed by the first step is passed to the second step.
You must update the content of the downstream data source of pipeline1 and run the pipeline again
You need to ensure the new run of pipeline1 fully processes the updated content.
Solution: Set the allow_reuse parameter of the PythonScriptStep object of both steps to False
Does the solution meet the goal?
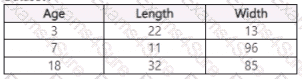
You use Azure Machine Learning Designer lo load the following datasets into an experiment:
Dataset1:
Dataset2:
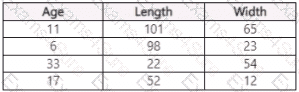
You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets.
Solution: Use the Add Rows component.
Does the solution meet the goal?
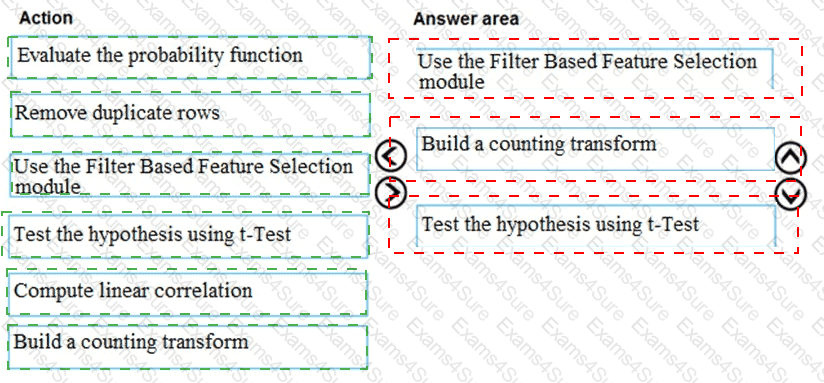
You are producing a multiple linear regression model in Azure Machine Learning Studio.
Several independent variables are highly correlated.
You need to select appropriate methods for conducting effective feature engineering on all the data.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


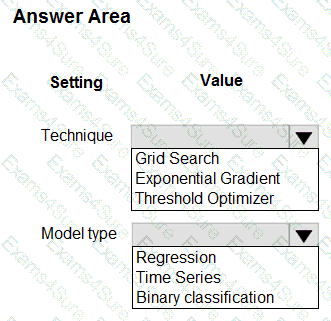
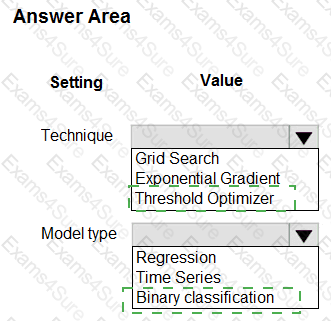
You have machine learning models produce unfair predictions across sensitive features.
You must use a post-processing technique to apply a constraint to the models to mitigate their unfairness.
You need to select a post-processing technique and model type.
What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it as a result, these questions will not appear in the review screen.
You use Azure Machine Learning designer to load the following datasets into an experiment:
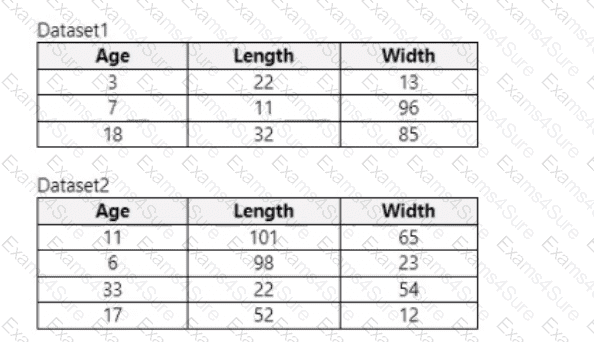
You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets.
Solution: Use the Apply Transformation module.
Does the solution meet the goal?
You have an Azure Machine Learning workspace. You plan to tune model hyperparameters by using a sweep job.
You need to find a sampling method that supports early termination of low-performance jobs and continuous hyperpara meters.
Solution: Use the Sobol sampling method over the hyperpara meter space.
Does the solution meet the goal?
You need to build a feature extraction strategy for the local models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.