
Professional-Machine-Learning-Engineer Practice Questions
Google Professional Machine Learning Engineer
Last Update 3 days ago
Total Questions : 296
Dive into our fully updated and stable Professional-Machine-Learning-Engineer practice test platform, featuring all the latest Machine Learning Engineer exam questions added this week. Our preparation tool is more than just a Google study aid; it's a strategic advantage.
Our free Machine Learning Engineer practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about Professional-Machine-Learning-Engineer. Use this test to pinpoint which areas you need to focus your study on.

You are collaborating on a model prototype with your team. You need to create a Vertex Al Workbench environment for the members of your team and also limit access to other employees in your project. What should you do?
Your team trained and tested a DNN regression model with good results. Six months after deployment, the model is performing poorly due to a change in the distribution of the input data. How should you address the input differences in production?
You are designing an architecture with a serverless ML system to enrich customer support tickets with informative metadata before they are routed to a support agent. You need a set of models to predict ticket priority, predict ticket resolution time, and perform sentiment analysis to help agents make strategic decisions when they process support requests. Tickets are not expected to have any domain-specific terms or jargon.
The proposed architecture has the following flow:
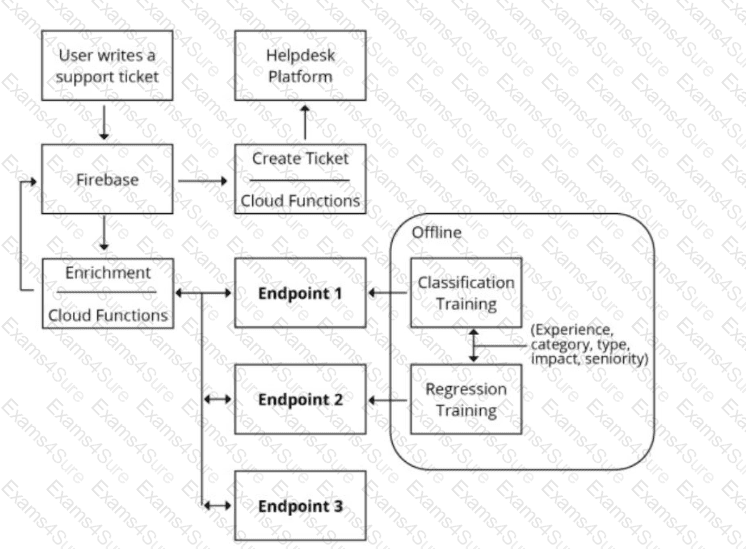
Which endpoints should the Enrichment Cloud Functions call?
You work at a bank. You need to develop a credit risk model to support loan application decisions You decide to implement the model by using a neural network in TensorFlow Due to regulatory requirements, you need to be able to explain the models predictions based on its features When the model is deployed, you also want to monitor the model ' s performance overtime You decided to use Vertex Al for both model development and deployment What should you do?
You work for an online publisher that delivers news articles to over 50 million readers. You have built an AI model that recommends content for the company’s weekly newsletter. A recommendation is considered successful if the article is opened within two days of the newsletter’s published date and the user remains on the page for at least one minute.
All the information needed to compute the success metric is available in BigQuery and is updated hourly. The model is trained on eight weeks of data, on average its performance degrades below the acceptable baseline after five weeks, and training time is 12 hours. You want to ensure that the model’s performance is above the acceptable baseline while minimizing cost. How should you monitor the model to determine when retraining is necessary?
You built a custom Vertex AI pipeline job that preprocesses images and trains an object detection model. The pipeline currently uses 1 n1-standard-8 machine with 1 NVIDIA Tesla V100 GPU. You want to reduce the model training time without compromising model accuracy. What should you do?
Your company stores a large number of audio files of phone calls made to your customer call center in an on-premises database. Each audio file is in wav format and is approximately 5 minutes long. You need to analyze these audio files for customer sentiment. You plan to use the Speech-to-Text API. You want to use the most efficient approach. What should you do?
You have trained a deep neural network model on Google Cloud. The model has low loss on the training data, but is performing worse on the validation data. You want the model to be resilient to overfitting. Which strategy should you use when retraining the model?
You are investigating the root cause of a misclassification error made by one of your models. You used Vertex Al Pipelines to tram and deploy the model. The pipeline reads data from BigQuery. creates a copy of the data in Cloud Storage in TFRecord format trains the model in Vertex Al Training on that copy, and deploys the model to a Vertex Al endpoint. You have identified the specific version of that model that misclassified: and you need to recover the data this model was trained on. How should you find that copy of the data ' ?
You have a functioning end-to-end ML pipeline that involves tuning the hyperparameters of your ML model using Al Platform, and then using the best-tuned parameters for training. Hypertuning is taking longer than expected and is delaying the downstream processes. You want to speed up the tuning job without significantly compromising its effectiveness. Which actions should you take?
Choose 2 answers

