
Professional-Machine-Learning-Engineer Practice Questions
Google Professional Machine Learning Engineer
Last Update 3 days ago
Total Questions : 296
Dive into our fully updated and stable Professional-Machine-Learning-Engineer practice test platform, featuring all the latest Machine Learning Engineer exam questions added this week. Our preparation tool is more than just a Google study aid; it's a strategic advantage.
Our free Machine Learning Engineer practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about Professional-Machine-Learning-Engineer. Use this test to pinpoint which areas you need to focus your study on.

You work for a retailer that sells clothes to customers around the world. You have been tasked with ensuring that ML models are built in a secure manner. Specifically, you need to protect sensitive customer data that might be used in the models. You have identified four fields containing sensitive data that are being used by your data science team: AGE, IS_EXISTING_CUSTOMER, LATITUDE_LONGITUDE, and SHIRT_SIZ
E.
What should you do with the data before it is made available to the data science team for training purposes?You recently built the first version of an image segmentation model for a self-driving car. After deploying the model, you observe a decrease in the area under the curve (AUC) metric. When analyzing the video recordings, you also discover that the model fails in highly congested traffic but works as expected when there is less traffic. What is the most likely reason for this result?
You have deployed a model on Vertex AI for real-time inference. During an online prediction request, you get an “Out of Memory” error. What should you do?
Your team is working on an NLP research project to predict political affiliation of authors based on articles they have written. You have a large training dataset that is structured like this:

You followed the standard 80%-10%-10% data distribution across the training, testing, and evaluation subsets. How should you distribute the training examples across the train-test-eval subsets while maintaining the 80-10-10 proportion?
A)

B)

C)

D)

You are developing a recommendation engine for an online clothing store. The historical customer transaction data is stored in BigQuery and Cloud Storage. You need to perform exploratory data analysis (EDA), preprocessing and model training. You plan to rerun these EDA, preprocessing, and training steps as you experiment with different types of algorithms. You want to minimize the cost and development effort of running these steps as you experiment. How should you configure the environment?
You are the lead ML engineer on a mission-critical project that involves analyzing massive datasets using Apache Spark. You need to establish a robust environment that allows your team to rapidly prototype Spark models using Jupyter notebooks. What is the fastest way to achieve this?
You have developed a fraud detection model for a large financial institution using Vertex AI. The model achieves high accuracy, but stakeholders are concerned about potential bias based on customer demographics. You have been asked to provide insights into the model ' s decision-making process and identify any fairness issues. What should you do?
Your team needs to build a model that predicts whether images contain a driver ' s license, passport, or credit card. The data engineering team already built the pipeline and generated a dataset composed of 10,000 images with driver ' s licenses, 1,000 images with passports, and 1,000 images with credit cards. You now have to train a model with the following label map: [ ' driversjicense ' , ' passport ' , ' credit_card ' ]. Which loss function should you use?
You work for a social media company. You need to detect whether posted images contain cars. Each training example is a member of exactly one class. You have trained an object detection neural network and deployed the model version to Al Platform Prediction for evaluation. Before deployment, you created an evaluation job and attached it to the Al Platform Prediction model version. You notice that the precision is lower than your business requirements allow. How should you adjust the model ' s final layer softmax threshold to increase precision?
You trained a text classification model. You have the following SignatureDefs:
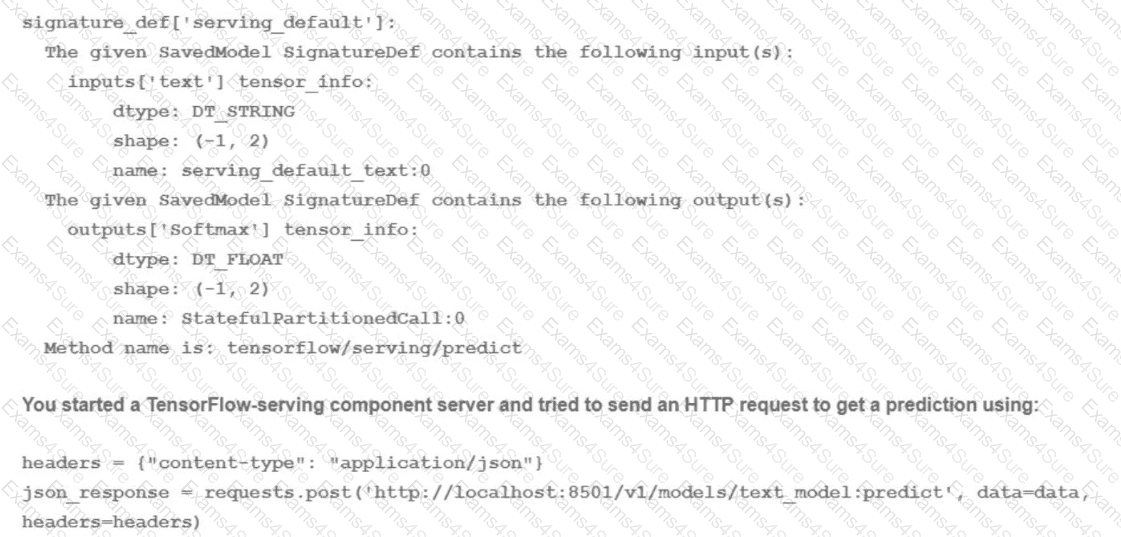
What is the correct way to write the predict request?

