
Professional-Machine-Learning-Engineer Practice Questions
Google Professional Machine Learning Engineer
Last Update 3 days ago
Total Questions : 296
Dive into our fully updated and stable Professional-Machine-Learning-Engineer practice test platform, featuring all the latest Machine Learning Engineer exam questions added this week. Our preparation tool is more than just a Google study aid; it's a strategic advantage.
Our free Machine Learning Engineer practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about Professional-Machine-Learning-Engineer. Use this test to pinpoint which areas you need to focus your study on.

You created an ML pipeline with multiple input parameters. You want to investigate the tradeoffs between different parameter combinations. The parameter options are
• input dataset
• Max tree depth of the boosted tree regressor
• Optimizer learning rate
You need to compare the pipeline performance of the different parameter combinations measured in F1 score, time to train and model complexity. You want your approach to be reproducible and track all pipeline runs on the same platform. What should you do?
You are building a TensorFlow model for a financial institution that predicts the impact of consumer spending on inflation globally. Due to the size and nature of the data, your model is long-running across all types of hardware, and you have built frequent checkpointing into the training process. Your organization has asked you to minimize cost. What hardware should you choose?
Your company manages an ecommerce platform and has a large dataset of customer reviews. Each review has a positive, negative, or neutral label. You need to quickly prototype a sentiment analysis model that accurately predicts the sentiment labels of new customer reviews while minimizing time and cost. What should you do?
You want to migrate a scikrt-learn classifier model to TensorFlow. You plan to train the TensorFlow classifier model using the same training set that was used to train the scikit-learn model and then compare the performances using a common test set. You want to use the Vertex Al Python SDK to manually log the evaluation metrics of each model and compare them based on their F1 scores and confusion matrices. How should you log the metrics?
Options:
A.

B.

C.
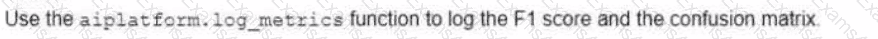
D.

Your work for a textile manufacturing company. Your company has hundreds of machines and each machine has many sensors. Your team used the sensory data to build hundreds of ML models that detect machine anomalies Models are retrained daily and you need to deploy these models in a cost-effective way. The models must operate 24/7 without downtime and make sub millisecond predictions. What should you do?
Your organization wants you to compare various, widely available ML models for Gen AI use cases. The models you plan to compare are also available on Google Cloud. You have received curated internal benchmark datasets from several teams for their specific use cases and tasks. You need to submit a comprehensive report of your recommendations. You want to evaluate the models using the most efficient approach. What should you do?
You trained a model on data stored in a Cloud Storage bucket. The model needs to be retrained frequently in Vertex AI Training using the latest data in the bucket. Data preprocessing is required prior to retraining. You want to build a simple and efficient near-real-time ML pipeline in Vertex AI that will preprocess the data when new data arrives in the bucket. What should you do?
You work at an organization that maintains a cloud-based communication platform that integrates conventional chat, voice, and video conferencing into one platform. The audio recordings are stored in Cloud Storage. All recordings have an 8 kHz sample rate and are more than one minute long. You need to implement a new feature in the platform that will automatically transcribe voice call recordings into a text for future applications, such as call summarization and sentiment analysis. How should you implement the voice call transcription feature following Google-recommended best practices?
You work at a leading healthcare firm developing state-of-the-art algorithms for various use cases You have unstructured textual data with custom labels You need to extract and classify various medical phrases with these labels What should you do?
You have been asked to productionize a proof-of-concept ML model built using Keras. The model was trained in a Jupyter notebook on a data scientist’s local machine. The notebook contains a cell that performs data validation and a cell that performs model analysis. You need to orchestrate the steps contained in the notebook and automate the execution of these steps for weekly retraining. You expect much more training data in the future. You want your solution to take advantage of managed services while minimizing cost. What should you do?

