
Professional-Cloud-DevOps-Engineer Practice Questions
Google Cloud Certified - Professional Cloud DevOps Engineer Exam
Last Update 2 days ago
Total Questions : 201
Dive into our fully updated and stable Professional-Cloud-DevOps-Engineer practice test platform, featuring all the latest Cloud DevOps Engineer exam questions added this week. Our preparation tool is more than just a Google study aid; it's a strategic advantage.
Our free Cloud DevOps Engineer practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about Professional-Cloud-DevOps-Engineer. Use this test to pinpoint which areas you need to focus your study on.

You are responding to a high-priority incident where a critical, user-facing payment service is experiencing a 50% error rate. The cause is a non-critical, batch analytics Dataflow pipeline flooding a shared Memorystore for Redis instance with writes, which has spiked read latency for the payment service. A full rollback of the Dataflow pipeline's deployment will take 15 minutes to complete through your CI/CD process. You need to restore the payment service as quickly as possible. What should you do?
Your team is building a service that performs compute-heavy processing on batches of data The data is processed faster based on the speed and number of CPUs on the machine These batches of data vary in size and may arrive at any time from multiple third-party sources You need to ensure that third partiesare able to upload their data securely. You want to minimize costs while ensuring that the data is processed as quickly as possible What should you do?
You are managing an application that runs in Compute Engine The application uses a custom HTTP server to expose an API that is accessed by other applications through an internal TCP/UDP load balancer A firewall rule allows access to the API port from 0.0.0-0/0. You need to configure Cloud Logging to log each IP address that accesses the API by using the fewest number of steps What should you do Bret?
You are working with a government agency that requires you to archive application logs for seven years. You need to configure Stackdriver to export and store the logs while minimizing costs of storage. What should you do?
You are performing a semi-annual capacity planning exercise for your flagship service You expect a service user growth rate of 10% month-over-month for the next six months Your service is fully containerized and runs on a Google Kubemetes Engine (GKE) standard cluster across three zones with cluster autoscaling enabled You currently consume about 30% of your total deployed CPU capacity and you require resilience against the failure of a zone. You want to ensure that your users experience minimal negative impact as a result of this growth o' as a result of zone failure while you avoid unnecessary costs How should you prepare to handle the predicted growth?
You are currently planning how to display Cloud Monitoring metrics for your organization's Google Cloud projects. Your organization has three folders and six projects:
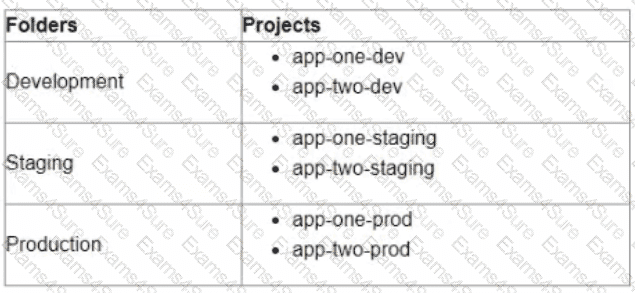
You want to configure Cloud Monitoring dashboards lo only display metrics from the projects within one folder You need to ensure that the dashboards do not display metrics from projects in the other folders You want to follow Google-recommended practices What should you do?
Your team is preparing to launch a new API in Cloud Run. The API uses an OpenTelemetry agent to send distributed tracing data to Cloud Trace to monitor the time each request takes. The team has noticed inconsistent trace collection. You need to resolve the issue. What should you do?
Your team is running microservices in Google Kubernetes Engine (GKE) You want to detect consumption of an error budget to protect customers and define release policies What should you do?
Your company runs an e-commerce business. The application responsible for payment processing has structured JSON logging with the following schema:
Capture and access of logs from the payment processing application is mandatory for operations, but the jsonPayload.user_email field contains personally identifiable information (PII). Your security team does not want the entire engineering team to have access to PII. You need to stop exposing PII to the engineering team and restrict access to security team members only. What should you do?
You are creating a CI/CD pipeline in Cloud Build to build an application container image The application code is stored in GitHub Your company requires thai production image builds are only run against the main branch and that the change control team approves all pushes to the main branch You want the image build to be as automated as possible What should you do?
Choose 2 answers

