Cloudera Certified Administrator for Apache Hadoop (CCAH)
Last Update 4 days ago
Total Questions : 60
CCA-500 is stable now with all latest exam questions are added 4 days ago. Just download our Full package and start your journey with Cloudera Certified Administrator for Apache Hadoop (CCAH) certification. All these Cloudera CCA-500 practice exam questions are real and verified by our Experts in the related industry fields.
You are running a Hadoop cluster with a NameNode on host mynamenode. What are two ways to determine available HDFS space in your cluster?
You have installed a cluster HDFS and MapReduce version 2 (MRv2) on YARN. You have no dfs.hosts entry(ies) in your hdfs-site.xml configuration file. You configure a new worker node by setting fs.default.name in its configuration files to point to the NameNode on your cluster, and you start the DataNode daemon on that worker node. What do you have to do on the cluster to allow the worker node to join, and start sorting HDFS blocks?
Which two features does Kerberos security add to a Hadoop cluster? (Choose two)
Your Hadoop cluster is configuring with HDFS and MapReduce version 2 (MRv2) on YARN. Can you configure a worker node to run a NodeManager daemon but not a DataNode daemon and still have a functional cluster?
Each node in your Hadoop cluster, running YARN, has 64GB memory and 24 cores. Your yarn.site.xml has the following configuration:
You want YARN to launch no more than 16 containers per node. What should you do?
You use the hadoop fs –put command to add a file “sales.txt” to HDFS. This file is small enough that it fits into a single block, which is replicated to three nodes in your cluster (with a replication factor of 3). One of the nodes holding this file (a single block) fails. How will the cluster handle the replication of file in this situation?
Your Hadoop cluster contains nodes in three racks. You have not configured the dfs.hosts property in the NameNode’s configuration file. What results?
You have a cluster running with the fair Scheduler enabled. There are currently no jobs running on the cluster, and you submit a job A, so that only job A is running on the cluster. A while later, you submit Job
B.
now Job A and Job B are running on the cluster at the same time. How will the Fair Scheduler handle these two jobs? (Choose two)Cluster Summary:
45 files and directories, 12 blocks = 57 total. Heap size is 15.31 MB/193.38MB(7%)
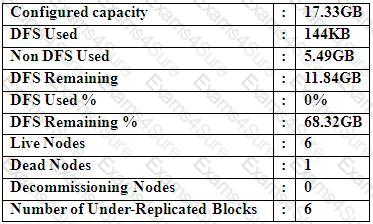
Refer to the above screenshot.
You configure a Hadoop cluster with seven DataNodes and on of your monitoring UIs displays the details shown in the exhibit.
What does the this tell you?


TESTED 27 Apr 2024
Hi this is Romona Kearns from Holland and I would like to tell you that I passed my exam with the use of exams4sure dumps. I got same questions in my exam that I prepared from your test engine software. I will recommend your site to all my friends for sure.
Our all material is important and it will be handy for you. If you have short time for exam so, we are sure with the use of it you will pass it easily with good marks. If you will not pass so, you could feel free to claim your refund. We will give 100% money back guarantee if our customers will not satisfy with our products.

