
MLA-C01 Practice Questions
AWS Certified Machine Learning Engineer - Associate
Last Update 4 days ago
Total Questions : 241
Dive into our fully updated and stable MLA-C01 practice test platform, featuring all the latest AWS Certified Associate exam questions added this week. Our preparation tool is more than just a Amazon Web Services study aid; it's a strategic advantage.
Our free AWS Certified Associate practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about MLA-C01. Use this test to pinpoint which areas you need to focus your study on.

An ML engineer is designing an AI-powered traffic management system. The system must use near real-time inference to predict congestion and prevent collisions.
The system must also use batch processing to perform historical analysis of predictions over several hours to improve the model. The inference endpoints must scale automatically to meet demand.
Which combination of solutions will meet these requirements? (Select TWO.)
A company is planning to create several ML prediction models. The training data is stored in Amazon S3. The entire dataset is more than 5 ТВ in size and consists of CSV, JSON, Apache Parquet, and simple text files.
The data must be processed in several consecutive steps. The steps include complex manipulations that can take hours to finish running. Some of the processing involves natural language processing (NLP) transformations. The entire process must be automated.
Which solution will meet these requirements?
A company wants to use large language models (LLMs) that are supported by Amazon Bedrock to develop a chat interface for the company ' s internal technical documentation. The company stores the documentation as dozens of text files that are several megabytes in total size. The company updates the text files often.
Which solution will meet these requirements MOST cost-effectively?
An ML engineer is developing a classification model. The ML engineer needs to use custom libraries in processing jobs, training jobs, and pipelines in Amazon SageMaker AI.
Which solution will provide this functionality with the LEAST implementation effort?
A company uses an Amazon SageMaker AI model for real-time inference with auto scaling enabled. During peak usage, new instances launch before existing instances are fully ready, causing inefficiencies and delays.
Which solution will optimize the scaling process without affecting response times?
A company has developed a new ML model. The company requires online model validation on 10% of the traffic before the company fully releases the model in production. The company uses an Amazon SageMaker endpoint behind an Application Load Balancer (ALB) to serve the model.
Which solution will set up the required online validation with the LEAST operational overhead?
A company wants to use large language models (LLMs) supported by Amazon Bedrock to develop a chat interface for internal technical documentation.
The documentation consists of dozens of text files totaling several megabytes and is updated frequently.
Which solution will meet these requirements MOST cost-effectively?
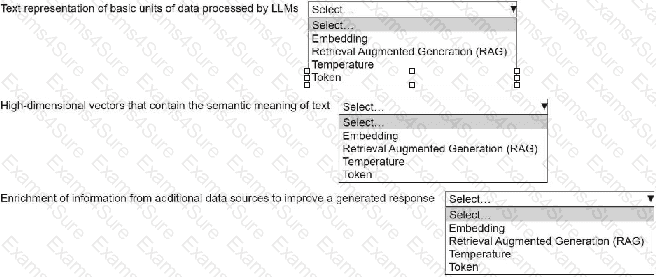
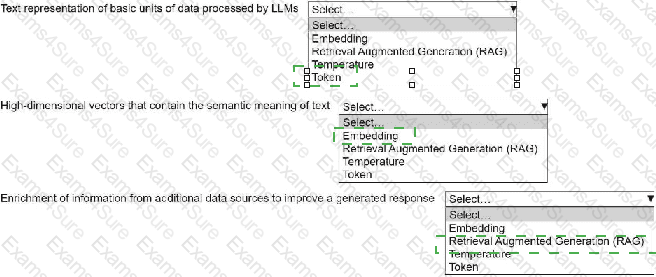
An ML engineer is building a generative AI application on Amazon Bedrock by using large language models (LLMs).
Select the correct generative AI term from the following list for each description. Each term should be selected one time or not at all. (Select three.)
• Embedding
• Retrieval Augmented Generation (RAG)
• Temperature
• Token

A company runs an ML model on Amazon SageMaker AI. The company uses an automatic process that makes API calls to create training jobs for the model. The company has new compliance rules that prohibit the collection of aggregated metadata from training jobs.
Which solution will prevent SageMaker AI from collecting metadata from the training jobs?
An ML engineer is analyzing a classification dataset before training a model in Amazon SageMaker AI. The ML engineer suspects that the dataset has a significant imbalance between class labels that could lead to biased model predictions. To confirm class imbalance, the ML engineer needs to select an appropriate pre-training bias metric.
Which metric will meet this requirement?

