
MLA-C01 Practice Questions
AWS Certified Machine Learning Engineer - Associate
Last Update 4 days ago
Total Questions : 241
Dive into our fully updated and stable MLA-C01 practice test platform, featuring all the latest AWS Certified Associate exam questions added this week. Our preparation tool is more than just a Amazon Web Services study aid; it's a strategic advantage.
Our free AWS Certified Associate practice questions crafted to reflect the domains and difficulty of the actual exam. The detailed rationales explain the 'why' behind each answer, reinforcing key concepts about MLA-C01. Use this test to pinpoint which areas you need to focus your study on.

A company regularly receives new training data from the vendor of an ML model. The vendor delivers cleaned and prepared data to the company ' s Amazon S3 bucket every 3-4 days.
The company has an Amazon SageMaker pipeline to retrain the model. An ML engineer needs to implement a solution to run the pipeline when new data is uploaded to the S3 bucket.
Which solution will meet these requirements with the LEAST operational effort?
An ML engineer is using Amazon Quick Suite (previously known as Amazon QuickSight) anomaly detection to detect very high or very low machine operating temperatures compared to normal. The ML engineer sets the Severity parameter to Low and above. The ML engineer sets the Direction parameter to All.
What effect will the ML engineer observe in the anomaly detection results if the ML engineer changes the Direction parameter to Lower than expected?
An ML engineer needs to process thousands of existing CSV objects and new CSV objects that are uploaded. The CSV objects are stored in a central Amazon S3 bucket and have the same number of columns. One of the columns is a transaction date. The ML engineer must query the data based on the transaction date.
Which solution will meet these requirements with the LEAST operational overhead?
A company is developing an application that reads animal descriptions from user prompts and generates images based on the information in the prompts. The application reads a message from an Amazon Simple Queue Service (Amazon SQS) queue. Then the application uses Amazon Titan Image Generator on Amazon Bedrock to generate an image based on the information in the message. Finally, the application removes the message from SQS queue.
Which IAM permissions should the company assign to the application ' s IAM role? (Select TWO.)
An ML engineer uses one ML framework to train multiple ML models. The ML engineer needs to optimize inference costs and host the models on Amazon SageMaker AI.
Which solution will meet these requirements MOST cost-effectively?
A company has an existing Amazon SageMaker AI model (v1) on a production endpoint. The company develops a new model version (v2) and needs to test v2 in production before substituting v2 for v1.
The company needs to minimize the risk of v2 generating incorrect output in production and must prevent any disruption of production traffic during the change.
Which solution will meet these requirements?
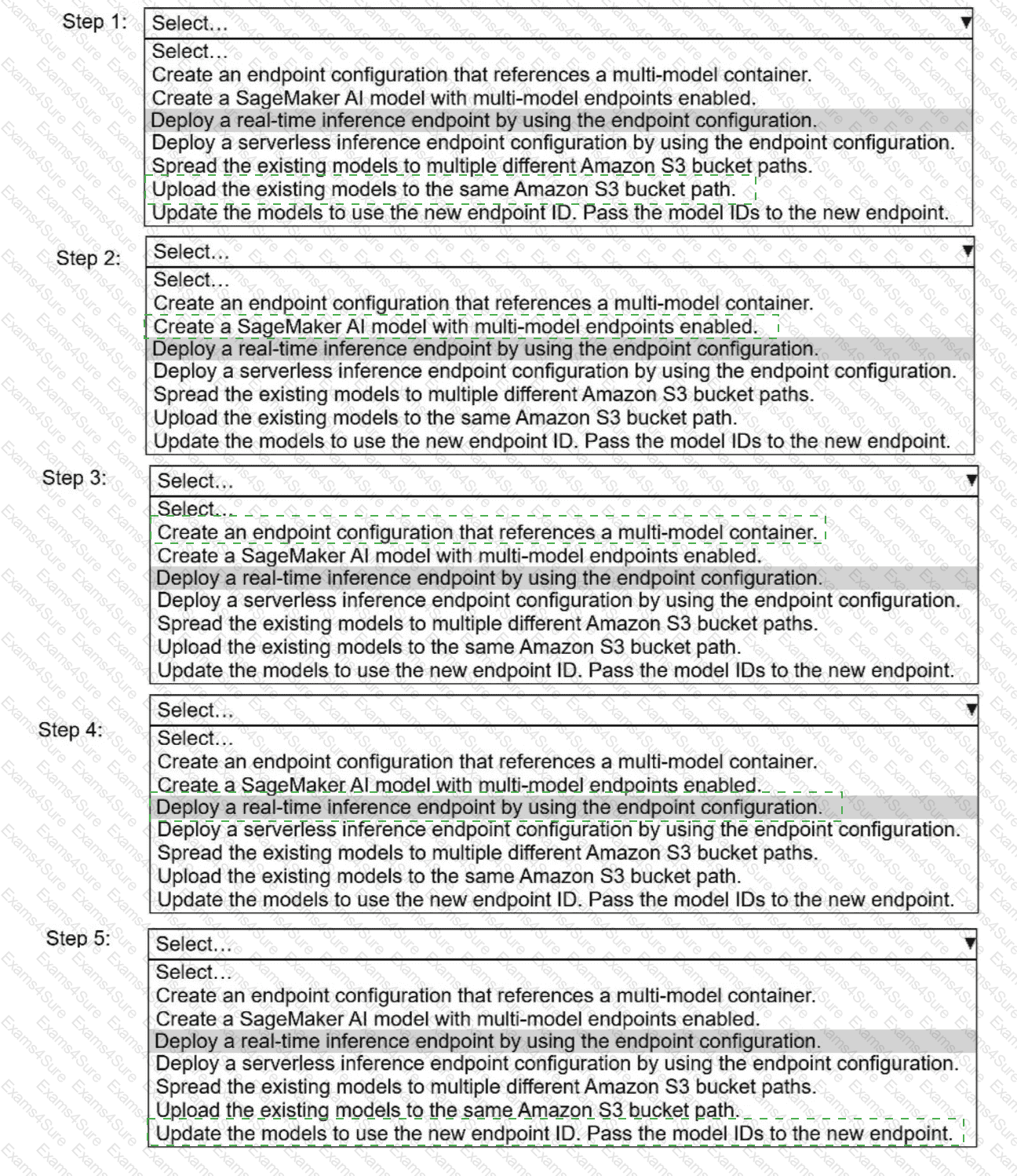
A company has built more than 50 models and deployed the models on Amazon SageMaker Al as real-time inference
endpoints. The company needs to reduce the costs of the SageMaker Al inference endpoints. The company used the same
ML framework to build the models. The company ' s customers require low-latency access to the models.
Select and order the correct steps from the following list to reduce the cost of inference and keep latency low. Select each
step one time or not at all. (Select and order FIV
E.
)· Create an endpoint configuration that references a multi-model container.
. Create a SageMaker Al model with multi-model endpoints enabled.
. Deploy a real-time inference endpoint by using the endpoint configuration.
. Deploy a serverless inference endpoint configuration by using the endpoint configuration.
· Spread the existing models to multiple different Amazon S3 bucket paths.
. Upload the existing models to the same Amazon S3 bucket path.
. Update the models to use the new endpoint I
D.
Pass the model IDs to the new endpoint.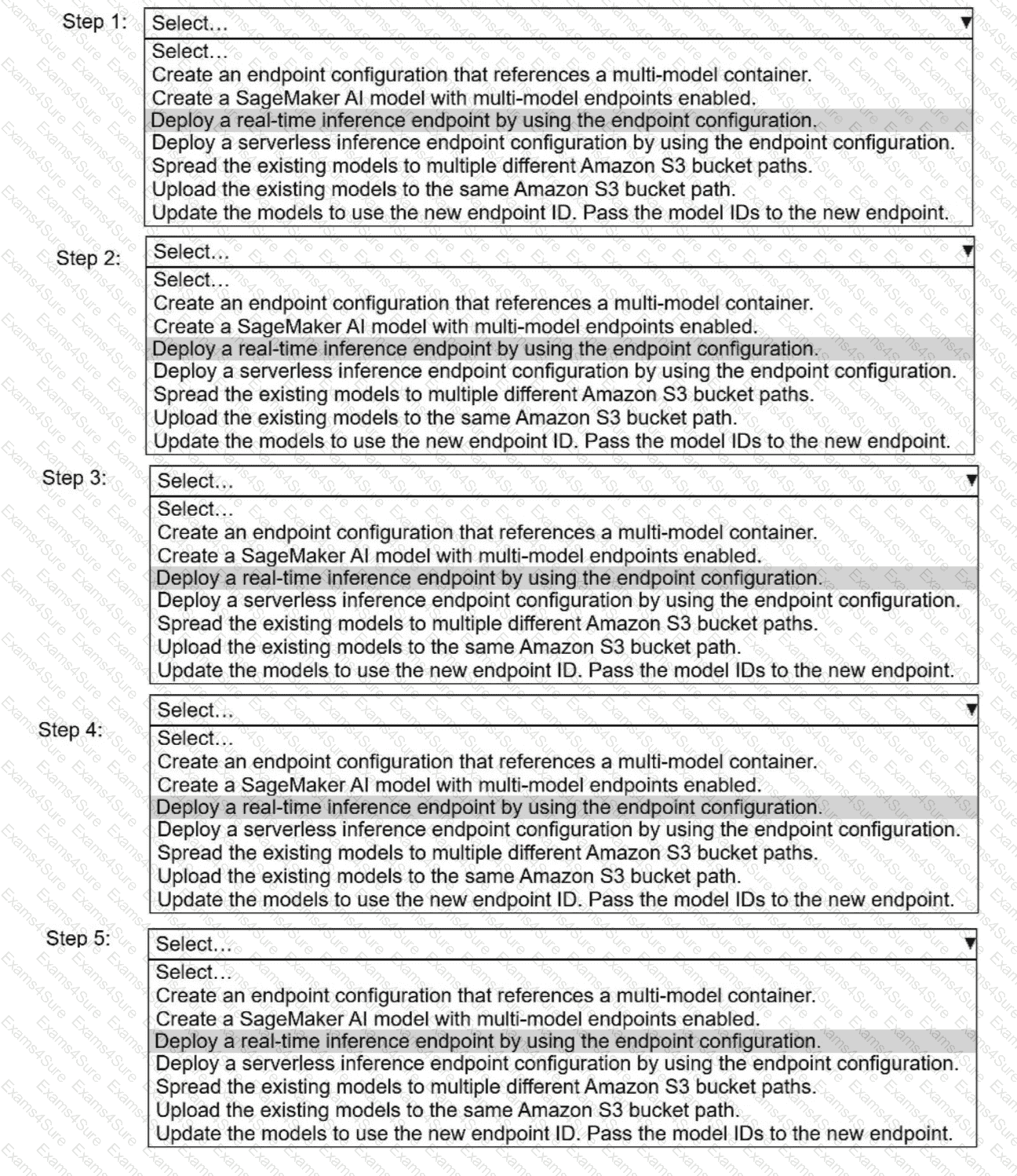
An ML engineer wants to run a training job on Amazon SageMaker AI. The training job will train a neural network by using multiple GPUs. The training dataset is stored in Parquet format.
The ML engineer discovered that the Parquet dataset contains files too large to fit into the memory of the SageMaker AI training instances.
Which solution will fix the memory problem?
A company has a team of data scientists who use Amazon SageMaker notebook instances to test ML models. When the data scientists need new permissions, the company attaches the permissions to each individual role that was created during the creation of the SageMaker notebook instance.
The company needs to centralize management of the team ' s permissions.
Which solution will meet this requirement?
A company uses Amazon SageMaker AI to create ML models. The data scientists need fine-grained control of ML workflows, DAG visualization, experiment history, and model governance for auditing and compliance.
Which solution will meet these requirements?

